Artificial Intelligence in the Chemical/Pharmaceutical Industry – Technology overview, current applications, and future research
Abstract
This article explores the role of artificial intelligence (AI) in the process industries such as the chemical and pharmaceutical industry. We start by classifying the most prominent technologies comprised under the generic term of AI, define them, and delineate their applicability in various functions along the organizational value chain. Further, we illustrate the boundary conditions for AI application by describing what data are required to initiate and sustain the ”intelligence” of algorithms. We continue with thought-provoking case studies that exemplify the status quo and possible future applications of AI in the chemical and pharmaceutical industry. Based on academic insights, we discuss potential barriers and pitfalls that firms might face while integrating AI into their business processes and present remedies.
1 Introduction
As the internet of things gains traction, new opportunities for value creation arise in the process industries through the availability of connectivity, data, and cloud computing. Recent estimates attribute artificial intelligence (AI) an annual value creation potential of over $100 billion in the chemical and pharmaceutical industry, respectively (Chui et al., 2018). Taking off on the physical infrastructure, new business models in the process industries increasingly place intangible assets like software, services, and data analysis on the center stage (Stoffels and Ziemer, 2017; Yoo et al., 2010). This constitutes a stark shift for companies operating in the process industries that are coined by high asset-intensity, integration into physical locations, and complex value chains (Lager et al., 2013). In order to gain a competitive edge over their competitors and realize the full technological potential of AI, companies are recommended to intertwine their business strategy with the use of new technologies (Bharadwaj et al., 2013), and then pervasively exploit the emerging opportunities in the company. The latter involves the kind of activity that is wired into the DNA of most companies in the process industries, which is innovation. Therefore, the goal of this paper is to support innovative applications and overall acceptance of AI in the process industries by pursuing two measures. First, we unravel the major strands of technologies comprised under the notion of AI and second, we draw on academic insights to discuss the applicability of AI in the context of two case studies. In the following, we focus on technologies that are either already extensively used or are likely to become major technology components in the future. Thus, the list of AI technologies is not complete but presents a snapshot of the most relevant technologies.
2 Technology overview of AI
Under the umbrella of AI, we identified four main technologies that appeared particularly important in the process industries, namely expert systems, neural networks, intelligent agents, and case-based reasoning. In the following, each methodology will be outlined in more detail.
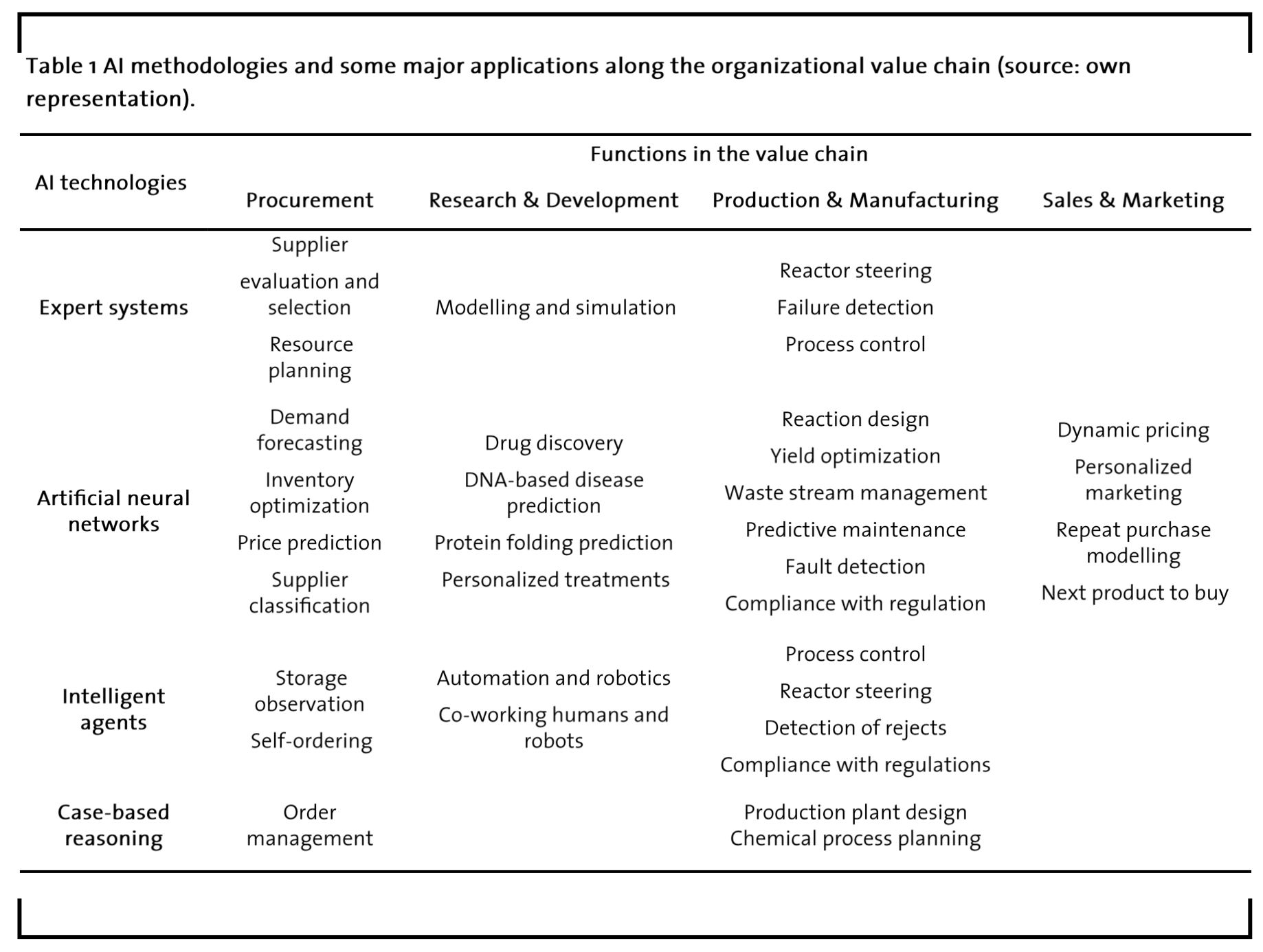
Starting with an overview of how AI is used for different functions along the value chain in research-intensive industries, Table 1 maps four AI technologies against major functions in companies.
2.1 Expert Systems
Expert systems (ES) are among the oldest and most widely used AI technologies (Negnevitsky, 2005). Their decision-making operates based on rules that are codified by the user in advance into the software that eventually presents a conclusion for a problem that otherwise needs expert reasoning. The coded rules serve as the knowledge base of the algorithms. On a technical level, the user feeds the algorithm with knowledge, which is commonly encoded in the form of If (antecedent) – Then (consequence) clauses. Take, for example, chess computers. Rules that account for the “smart” might look like these: If the pawn is on front of a competitor´s figure, Then it can neither walk forward nor capture the opponent’s figure because it can merely capture figures diagonal forward. Programming a rule-based ES for a specific application conventionally requires an expert in the respective field of application to collaborate with a programmer who translates the expert knowledge into code. However, the usefulness of this type of AI not only depends on the quality of the hard-coded rules but also on the newly fed data and facts that constitute the foundation of the reasoning process (Negnevitsky, 2005).
After the knowledge base has been filled with rules, new facts that capture the user’s problem can be filed into the expert system. Figure 1 presents the architecture of rule-based ES, including i) a knowledge base (comprising rules), ii) a database (comprising the facts), iii) an inference engine, iv) explanation facilities, v) and a user interface. When mimicking expert reasoning, these components interfere in the ways described in the following.
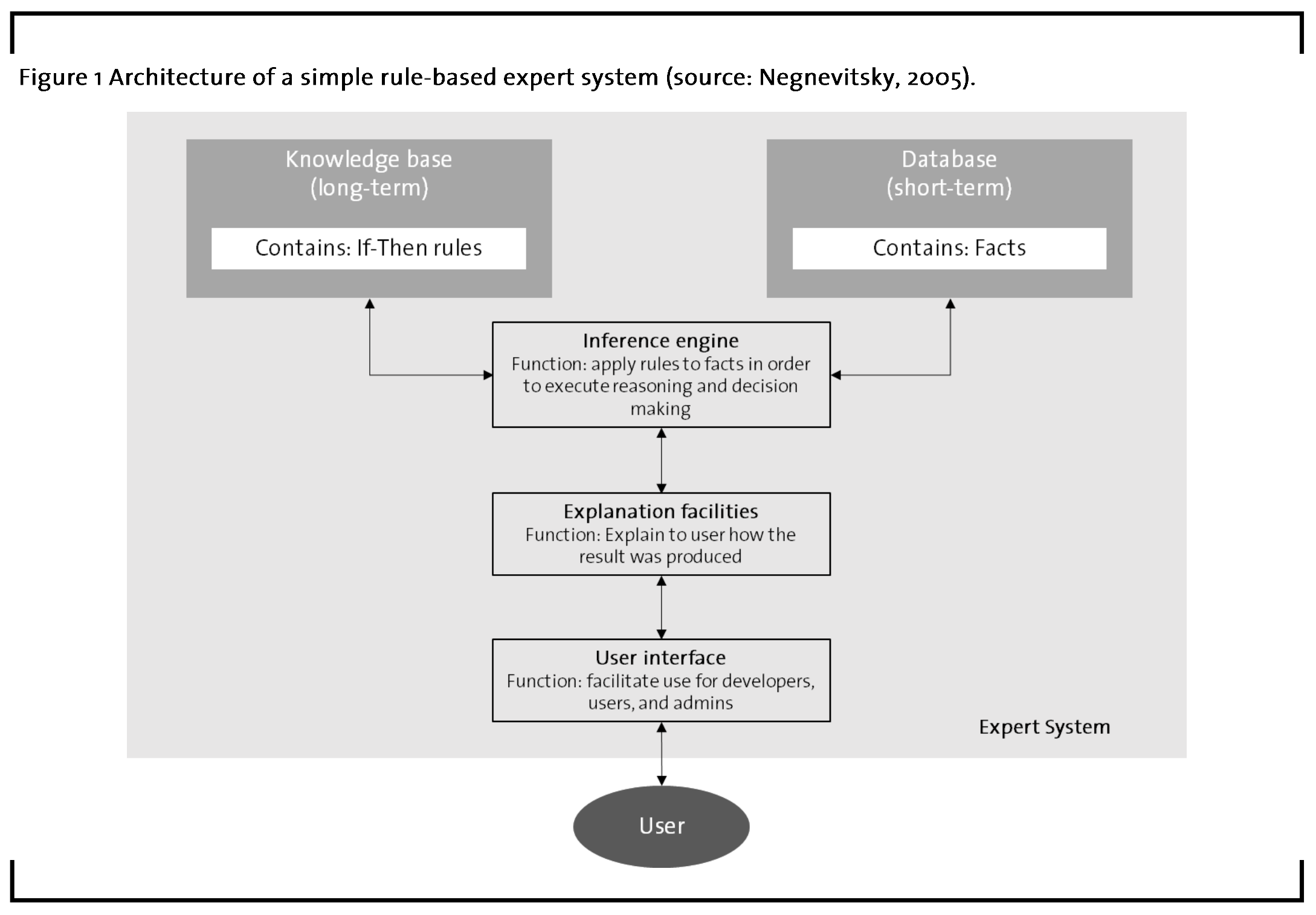
The inference engine is where the “intelligent” work takes place. Here, the rules that are encoded via If-Then relationships in the knowledge base are applied to the data or facts of the respective situation for which reasoning is required. When the “If” condition in the rule is fulfilled by the data, the “Then” i.e. the action is executed and the inference engine eventually delivers a result based on the given facts. In order to make the reasoning process more transparent, explanation facilities are embedded between the inference engine and the user. They enable users to ask how a result was produced and why specific facts are needed (Negnevitsky, 2005). Explanation facilities therefore bridge the gap between the rules and the outcome so that the result presented to the human user is comprehensible. Finally, the user interface needs to be designed in a way that suits the IT-skills of common users. Conventionally, interfaces are designed to be simple and intuitive, so that even non-experts have easy access to the knowledge condensed in the rule-based ES.
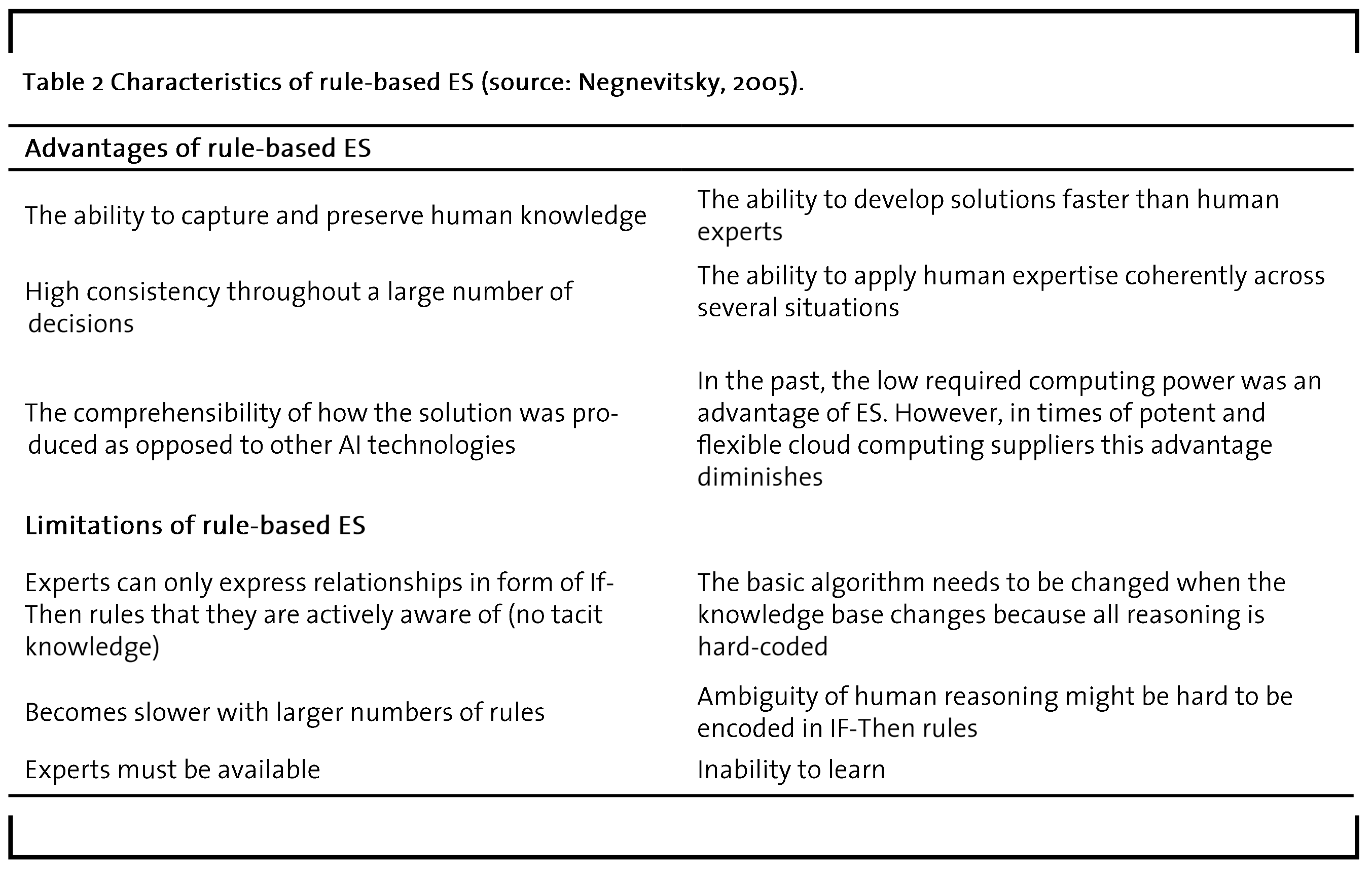
In terms of their application, rule-based ES are able to deliver value in situations where expert knowledge is available and can be purposefully captured in a system that then applies it to specific problems. The capabilities of ES include expressing relations, making recommendations, suggesting directives, strategies, and heuristics (Mohd Ali et al., 2015). Due to these abilities, rule-based ES have been applied in the context of strategic goal setting, planning, designing, scheduling, fault monitoring and diagnosis applications (Abraham, 2005). A major advantage of rule-base ES over novel methodologies such as deep learning with artificial neural networks is that their reasoning process is comprehensible for humans (Giarratano and Riley, 1989). This is especially important in situations where the AI’s decisions might have legal consequences such as in medical contexts. Table 2 presents some major advantages and disadvantages of rule-based ES.
2.2 Artificial neural networks
According to recent estimations, artificial neural networks (ANNs) have the potential to create an additional annual value of $100-200 billion in the chemical industry and around $100 billion in pharmaceuticals (Chui et al., 2018). Although ANNs have been around for several decades, they have long been unable to unfold their potential for pervasive application. Complementary forces that render ANNs more widely applicable today include the exponentially increasing computing power following Moore’s law1, cheap and small sensors, the resulting availability of data, and cloud computing (McAfee and Brynjolfsson, 2017). These mutually reinforcing elements have multiplied the applicability of ANNs, so that widespread application is reported in the chemical (Mohd Ali et al., 2015) and pharmaceutical industry (Agatonovic-Kustrin and Beresford, 2000; Zhavoronkov, 2018).
1 Moore’s law states that the number of transistor’s per integrated circuit doubles every 18-24 months. In consequence, smaller and faster devices are affordable for the same amount of money. Note that the continuous doubling follows a logarithmic function.
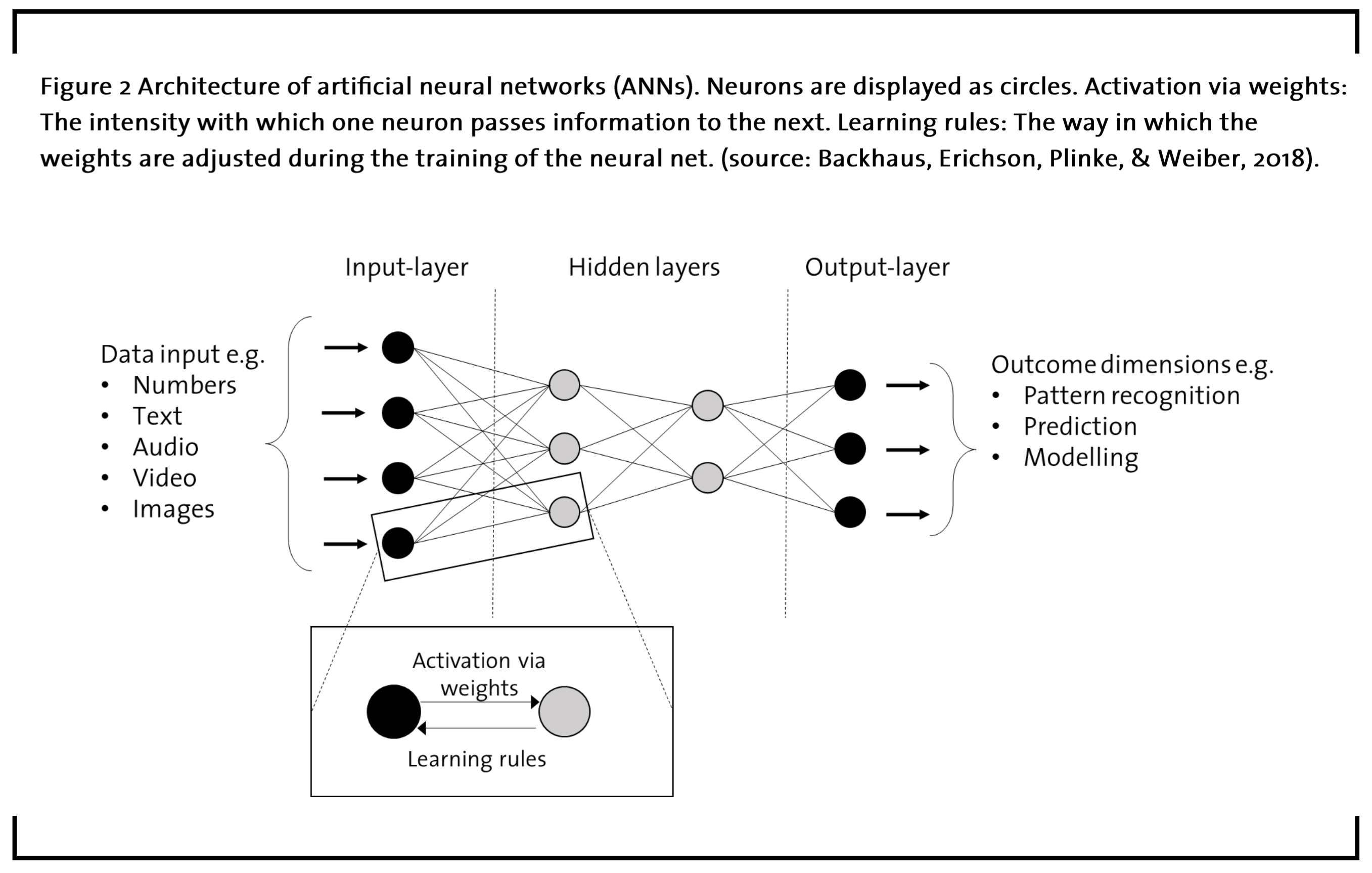
The technological architecture of ANNs is inspired by the nervous system of the human brain. ANNs adopt the idea of neurons as the smallest operating unit, which if interlinked in a network, can perform complex tasks. A schematic representation of such a network is shown in figure 2. The main constituents of ANNs are the different types of layers of neurons that are interconnected in a network. These include an input-layer, a problem-specific amount of hidden layers, and an output-layer. The input layer receives all information to be included in the reasoning process of the ANN. One of ANN’s major advantages in comparison with established technologies such as regression analysis is its ability to incorporate largely heterogeneous sources of information (Backhaus et al., 2016). For example, a neural net for predictive maintenance might include a database with numbers, images, and audio input from microphones in the plant. The hidden layers serve to extract patterns in the data that are then used to generate the outcome. Regarding the number of hidden layers, practitioners face a trade-off between using enough hidden layers to reach a fair level of accuracy on the one side and “overfitting” the network at the cost of the results’ generalizability on the other (Srivastava et al., 2014). Finally, the output-layer returns the intended outcome dimension.
At the level of the inter-neuron relationship depicted in figure 2, the activation of a focal neuron is contingent on the signals it receives from the neurons in the preceding layer. Most commonly, the weighted sum over all inputs signals is used to determine in how far the neuron is activated and consequently passes on its signal to the following layer (Backhaus et al., 2016). During the setup of the neural net, the input data determines the initial weights that the connections between neurons have. At the end of the training phase, the value of these weights represent the memory of the neural net (Agatonovic-Kustrin and Beresford, 2000). Due to the forward-oriented flow of information between neurons, this mode of training the network is referred to as “feedforward”. In order to optimize ANNs for their application, they are exposed to feedback and learning in subsequent iterations. For this means, learning rules are responsible for slightly readjusting the weights between neurons from the output backwards to the input layer, until the neural network has reached the intended level of accuracy. The iteration of this so-called backpropagation mechanism is the actual training of the neural net. After a satisfactory level of precision has been achieved through training, the ANN can be fed with new data and fulfil its actual purpose.
According to a study from McKinsey including several hundred use-cases, ANNs have large potential to generate additional value in areas where IT tools such as regression, estimation, and clustering are already in place (Chui et al., 2018). They further estimate that in 69% of their use cases ANNs provide incremental improvements over the technologies already used, while only 16% are applications in which no other analytics technique could deliver value. Although 16% appear small in comparison, there is considerable potential for industry disruption immanent in these digits. Additionally, in the remaining 15% of the cases ANNs cannot beat conventional analytics, since the application of ANNs is inextricably tied to the existence of sufficient training data. If the cost of gathering these data exceeds the value to be extracted from it, then, for example, a regression analysis or an expert system might be superior choices. However, because of the recent availability of data for training ANNs, the importance of rule-based ES is likely to fade and ANNs will take their place because of their superior capabilities (McAfee and Brynjolfsson, 2017).
A recent example of the power of ANNs to solve vastly complex problems is its performance in predicting the folding of a protein based on its DNA sequence. A team of Google-affiliated researchers created a neural net the called AlphaFold, which predicted the folding of complex proteins starting from scratch and significantly outperformed renowned teams in a worldwide prediction tournament (Evans et al., 2018).
2.3 Intelligent agents
Intelligent agents are referred to as autonomous components of a larger system, e.g. a production process in a chemical plant. They pursue their own agenda or goal but simultaneously interoperate with the other components in the systems (Franklin and Graesser, 1996). In many cases, multiple intelligent agents are connected in so-called multi-agent systems. For example, these include industrial process control systems or robots, where sensors feed information from the outside world into the system that then decides whether it should act on the situation or not. However, different agents might have conflicting goals about what actions to take in a specific situation, which is why a coordinating unit that aligns the various interests stemming from the individual agents might be useful (Bellifemine et al., 2007). Part of the agent system are effectors such as speakers, screens, stirrers, pumps, etc. through which the desired actions can be performed. In sum, intelligent agents feature the following characteristics (Wooldridge and Jennings, 1994):
- Autonomy: Intelligent agents operate without human intervention and supervise their own actions.
- Collaboration: Intelligent agents cooperate with other agents or humans to achieve its goals.
- Reactivity: Intelligent agents perceive the environment and react to environmental changes.
- Pro-Activity: Intelligent agents show goal-orientated behavior by taking initiative risks.
The interaction process of intelligent agents with their environment is presented in figure 3. The agent is programmed to independently identify an effective way to act upon its environment to achieve its goals. The sensor-based perception in combination and the effectors are the physical backbone of the system (Bellifemine et al., 2007). On the level of the algorithms, the agent evaluates possible actions in terms of whether they manipulate the environment in direction of the agent’s goals. As a result of this reasoning process, the agent will use its effectors to execute the action that will move it towards fulfilling its objectives (Russell and Norvig, 2010).
A powerful way to multiply the capabilities of individual agents is to connect them in a system. In these multi-agent systems (MAS), numerous agents with restricted capabilities cooperate in order to pursue the goals of a larger system (Franklin and Graesser, 1996). To this means, data processing and decision making is centralized to gain a larger picture of the environmental status quo, which, in turn, determines what actions shall be performed (Russell and Norvig, 2010). Take, for example, the process control system of a chemical plant. A variety of sensors is used to observe the reactions and all information is gathered and supervised in the process control centre. The overarching goal is to optimize the reaction parameters, which resolves potentially conflicting micro-goals of individual agent units. As becomes evident from this example, multiple agent systems often include an interface to connect to human experts in order to harness their knowledge and give them the opportunity to interfere in special situations.
However, as intelligent agents can be coupled with neural networks that are able to store experts’ ‘intuition’ of how to conduct a chemical process, the window of opportunity for human intervention is narrowing. As Porter and Heppelmann (2014) argue, the applicability of smart connected systems such as multiple agent systems are gradually shifting from mere monitoring over to control, optimization and eventually towards fully autonomous systems with high degrees of proactive behaviour.
2.4 Case-based reasoning
Case based reasoning (CBR) builds on the notion that ‘similar problems have similar solutions’. It is therefore related to how humans learn from experience. The foundation of this methodology is a database with previous cases that include a description of a problem and the respective solution. Figure 4 shows the most common framework for performing CBR, which is known as the CBR cycle (Aamodt and Plaza, 1994).
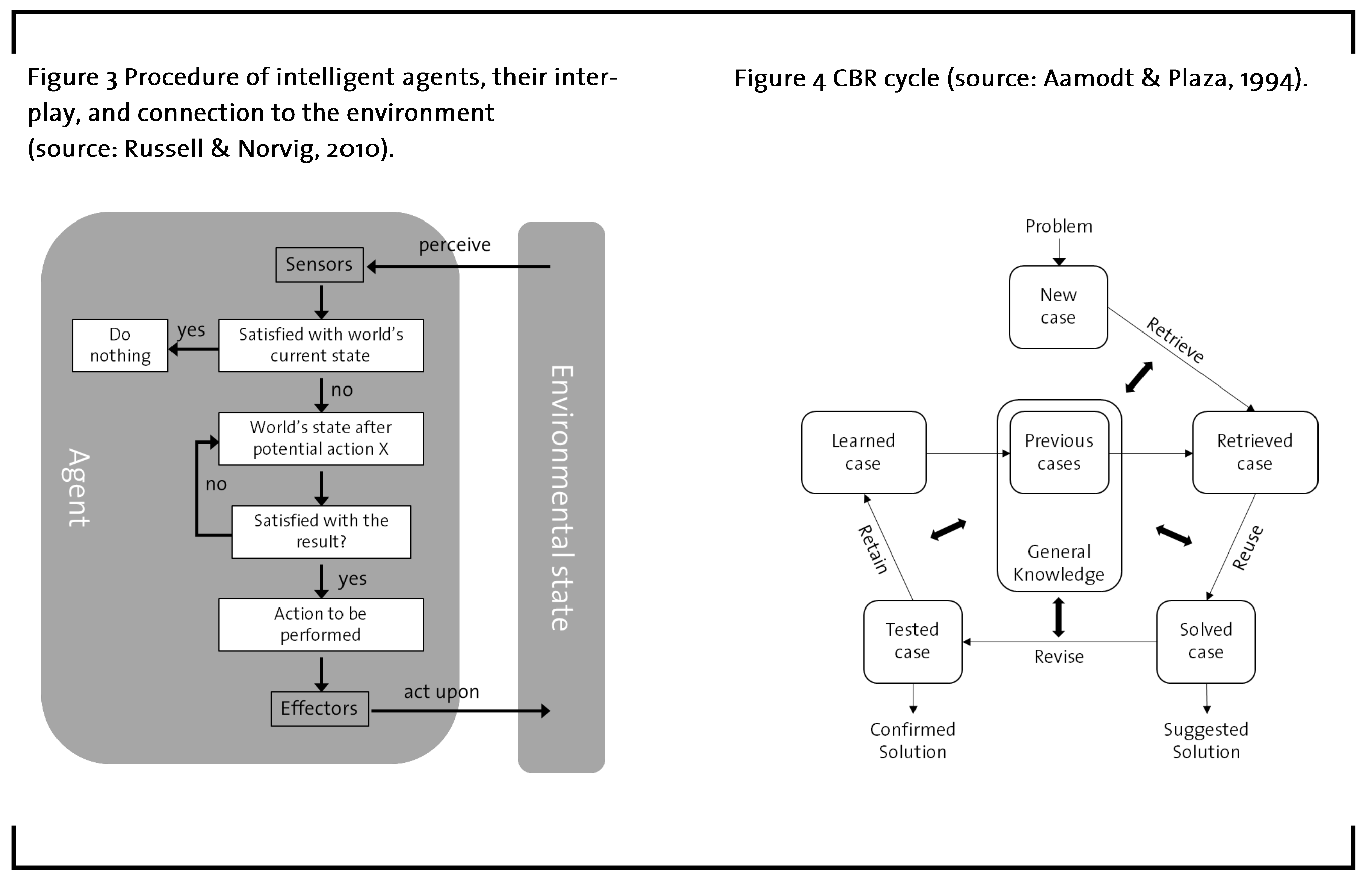
In CBR, every problem to be solved is treated as a new case. Initially, the relevant parameters that characterize the case like e.g. feed components and product purity requirements need to be filed into the system. In order to find a suitable solution, the characteristics of the new case are matched against those from previous cases and the ones with the highest overlap are retrieved. The collection of similar cases subsequently constitutes the foundation for solving the new case. After a solution for the new problem has been proposed by the algorithm, the newly solved case is revised and eventually added to the database so that the knowledge repository expands over time (Aamodt and Plaza, 1994).
CBR systems are often used in combination with ANNs, since they have complementary capabilities. While CBRs can make a purposeful preselection of cases that will be considered for the reasoning process, ANNs are good at encoding the distinct characteristics into complex patterns stored in their hidden layers. Together, the two systems represent an efficient means for solving complex problems based on a history of relevant cases without sacrificing the comprehensibility of the outcome (Li et al., 2018).
3 Case studies
3.1 AI in drug discovery – The case of Deep
Genomics
The application of AI in medicine has matured and now offers capabilities that are particularly useful for the design of medical treatments (Patel et al., 2009; Wainberg et al., 2018). In this regard, harnessing the pattern-recognition capacity of artificial neural networks is the most common approach. Based on this technology, numerous startups strive to complement the resource-rich incumbent firms with an AI-based approach to make research for new treatments more efficient. Take the example of Deep genomics, a Toronto-based startup founded in 2015. Their aim is to create personally tailored genetic medicine by utilizing AI to determine how DNA variations might produce specific diseases.
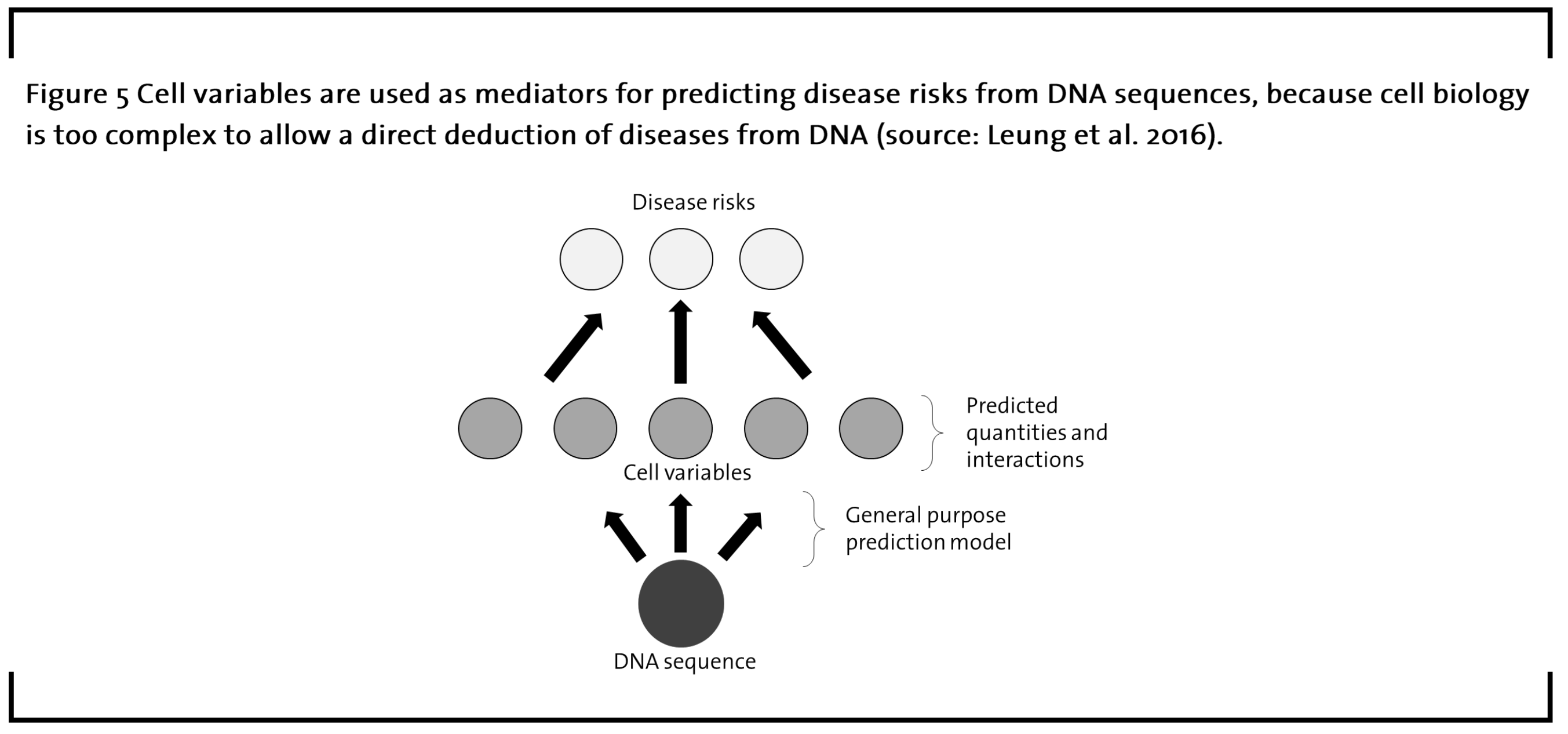
Recent advances in cell biology, automation, and AI enable treatments that are individualized at the level of the DNA. Despite the vast amount of data that is available for creating neural nets that deduce disease risks directly from the DNA, these direct prediction models turned out to be nontransparent and therefore not very useful in this highly regulated context. Due to the complex and interlinked processes in the body, researchers use so-called cell variables as mediators that bridge the wide logical gap between DNA sequences and disease risks (Leung et al., 2016), as figure 5 presents. These cell variables are factors that represent the processes in the cell such as the quantities of key molecules and interaction predictions (Leung et al., 2016). Based on information gained from high-throughput screening under various conditions, Deep Genomics uses the data on DNA sequences and related cell variables to train a neural net, therefore teaching it a general-purpose model. In the next step, deviations in cell variables are related to disease risks, creating a mediated link to the DNA sequence that accounts for the biological complexity of the cell. Thus, the algorithms is taught which DNA sequences are connected to what kind of circumstances in the cell, which in turn relates to the resulting diseases. In combination with newly developed gene editing technology such as CRISPR/Cas (Cong et al., 2013), unprecedented opportunities for personalized medicine arise.
In order to preselect promising target molecules that can eventually be tested in the lab, Deep Genomics has set up a platform database including over 69 billion molecules and tested them against 1 million targets in silico. This approach yielded 1000 promising compounds that delivered the intended effect on the biology of the cell. These molecules have effects on the cell variables used as mediators in the learning model. As a result of their in silico expertise, Deep Genomics scheduled first clinical trials in 2020 (Lohr, 2018). Thus, neural networks can guide the selection of potential treatment candidates but they cannot fully rule out the need for extensive practical testing in clinical trials.
3.2 AI in the laboratory – The case of Clever!Lab
Despite the value that artificial intelligence already delivers in scientific R&D, the wet chemistry routinely done in many laboratories is still performed in a mostly analogue manner. Insofar, laboratories as the cradle of innovation might hold large innovation potential that pioneering companies now strive to exploit using AI. Intelligent agents in combination with ANNs seem to be the most suitable combination for creating value with AI in the laboratory. Combining these two approaches, the enterprise Clever!Lab offers a smart assistant for upgrading everyday work in the laboratory with AI. Using cameras and microphones as agents and building on IBM Watson, the clever digital assistant strives to excel the capabilities of a digital laboratory journal and connects data on an overarching level, potentially augmenting efficiency and enabling innovation. The combination of a multiple agent system with an artificial neural network is a classic example of a hybrid AI system.
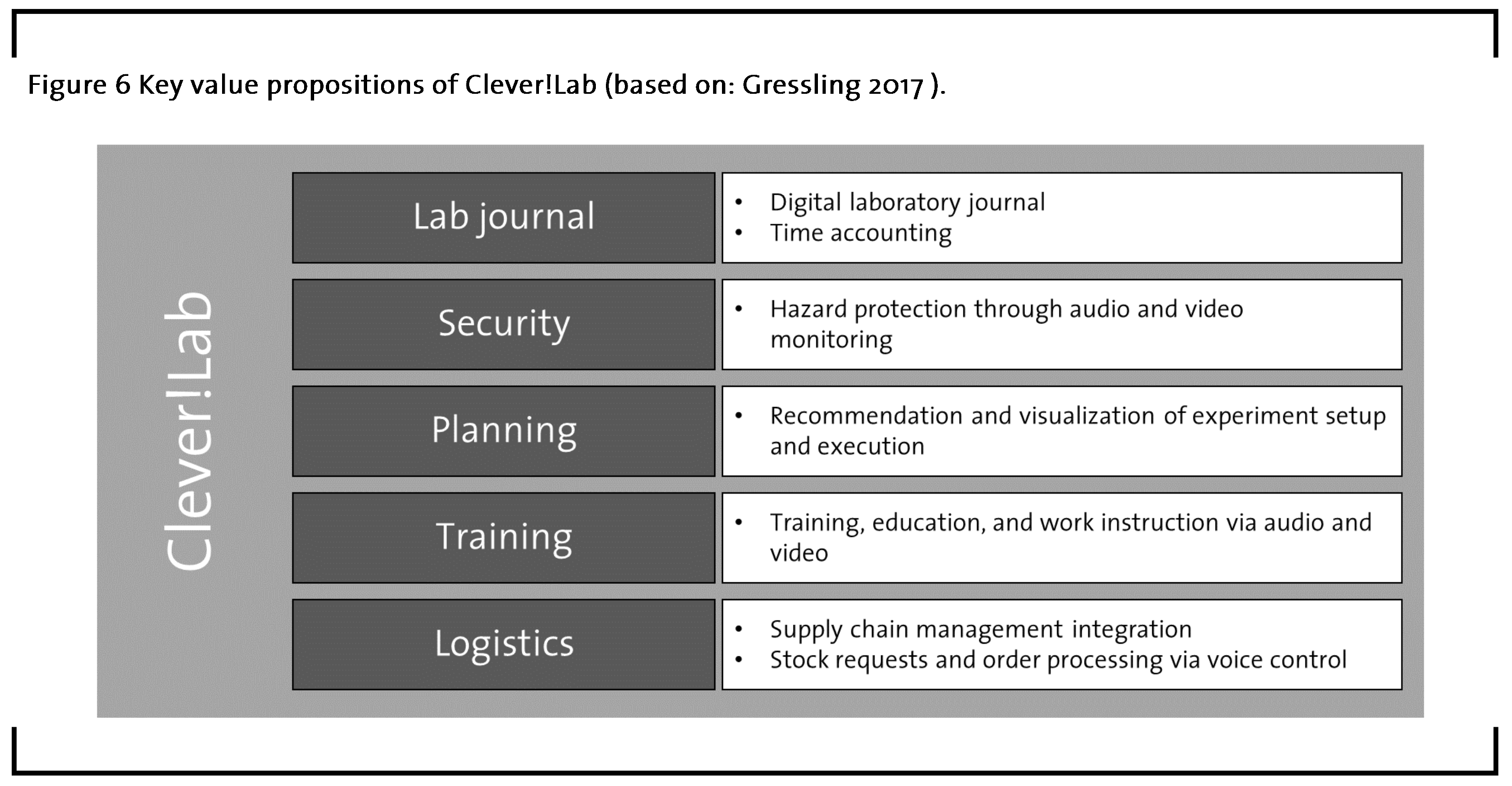
Clever!Lab conceptualizes their value proposition based on five pillars (Gressling, 2017), as depicted in figure 6. First, their solution comprises a digital lab journal that stores results in a coherent manner across all staff, thus, standardizing the results from routine analyses so that deep learning with ANNs can find hidden patterns in the data. To communicate findings to the clever assistant, employees may comfortably dictate their results via microphone, while personal accounts for all employees keep track of their time accounts, making individual notation obsolete. Second, the clever agent might assist in augmenting lab safety. For instance, cameras with infrared function can readily alert employees if a reaction overheats or when they forgot to put on their safety glasses. The third pillar is concerned with planning the reaction schedule and experiment setup. The hybrid AI might not only prevent bottlenecks on popular laboratory devices and therefore contribute to higher efficiency, but also directly assist by projecting reaction setups directly into the fume hood if needed. Fourth, implementing AI in the laboratory offers considerable opportunities for training and education. For example, employees could be supervised when trying new analyses and receive immediate feedback. Simulations of special events such as emergency alerts are also conceivable in this domain. Finally, having an interface to the firm’s supply chain management would allow the AI to keep account of all resources needed for the scheduled experiments and initiate timely purchases if any material runs short. Immediate orders via voice might also be possible. In addition, a useful feature might be to ensure and document that workflows comply with relevant regulation.
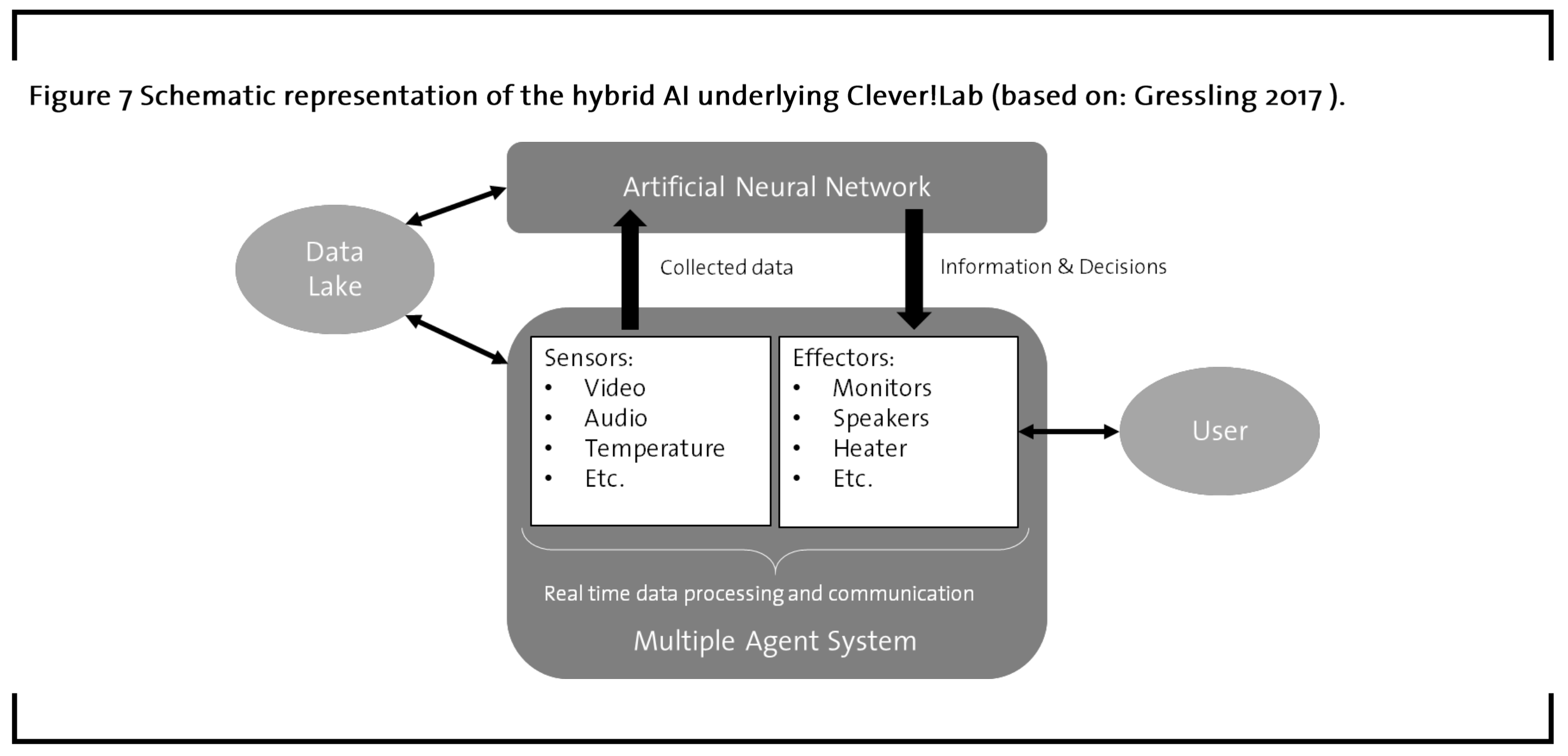
Regarding the technological requirements of smart laboratories, figure 7 illustrates the basic setup of how agent-based neural networks might interact with lab workers. The interface with the user is managed by the intelligent agent system that comprises sensors to receive information from the environment and effectors to interact with it. These sensors might include audio, video, temperature, humidity, etc. and potential effectors such as monitors, speakers, heating, among many other conceivable functionalities. A central position in the system is taken by the data lake that is ideally nurtured by the sensors and many other sources of knowledge such as scientific publication databanks and molecular libraries. The data lake constitutes the knowledge repository that underlies the reasoning processes of the system. Coupling the agent system with a neural network introduces the capability to analyze complex relationships in the data lake. For example, neural networks have made striking contribution in domains as complex as retrosynthesis planning, where hybrid approaches including neural networks have recently made a huge leap forward, as has been reported in Nature (Segler et al., 2018). Neural networks can extract patterns from noisy and heterogeneous types of data such as audio, video, and images. In congruence with the hybrid system’s goals, the neural net provides information and decisions that flow to the effectors for being transmitted to the user.
AI has the potential to deliver considerable value in the laboratory, but nothing comes without costs. In order to enable hybrid AI systems to unfold its more advanced functionalities, some major technical preconditions need to be met. At the center of the collaboration between lab workers and intelligent agent lies their communication. However, our human language is hard to understand for machines because it is ambiguous and work environments are often complex (Xiong et al., 2018). For this means, Clever!Lab builds on IBM Watson as the backbone of the intelligent agent, which readily enables sense-making from conversation. The analytical power of the neural net increases with the amount of information it gets from its environment. Although the internet of things is a strong driver of pervasive connectedness between devices, the longevity of old analogous machinery may currently hinder the exchange of relevant information between analytical devices such as chromatography systems and the digital assistant. In addition to necessary technological conditions, new technology needs to be adopted by employees in order to unfold its value, a topic that we discuss in the following chapter.
4 AI adoption in incumbent firms – The technology acceptance model
In the following, we discuss the potential organizational challenges of AI application, suggest remedies, and derive implications for firms operating in the process industries. For this means, we introduce and discuss the technology acceptance model (TAM) in order to deduce success factors for firms that strive to create value by applying AI throughout their businesses.
The implementation of new information systems is often not only costly, but might even fail (Legris et al., 2003). Therefore, research on the adoption of information technology in organizations has received considerable academic and managerial attention. Among others, academic researchers have developed and extensively tested a framework briefly termed TAM (Venkatesh and Davis, 2000). The goal of this framework lies in explaining the employees’ usage behavior regarding novel information technology. Beyond the application of AI in the case studies presented above, AI is argued to be a general purpose technology such as the steam engine, electricity, or computers that has the potential to create profound value throughout all industries (Brynjolfsson at al., 2018). In order to leverage the 100-200 billion dollars of potential annual value creation projected by McKinsey for the use of neural networks in the chemical industry alone (Chui et al., 2018), employees must be willing to embrace new AI-based solutions at the sacrifice of some of their old working habits. Figure 8 illustrates the relationships between major factors that drive technology adoption in form of actual usage behavior in firms.
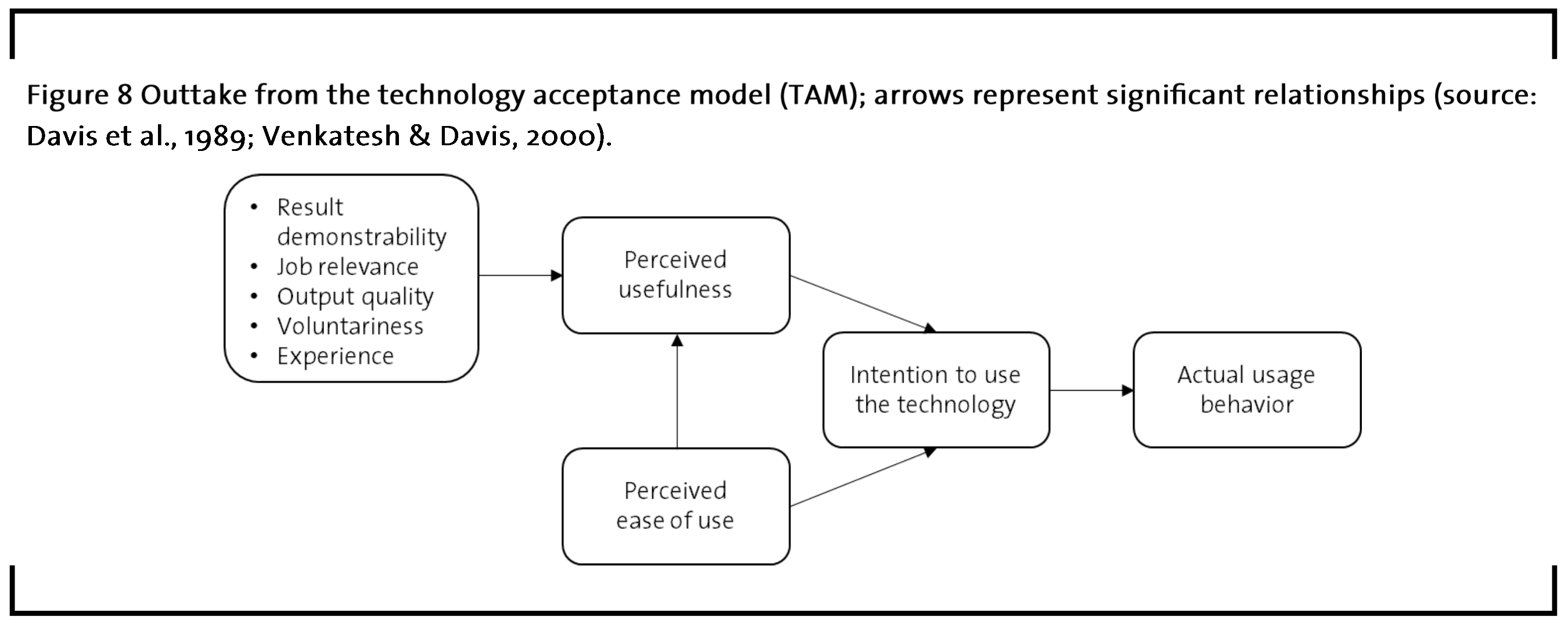
The employees’ actual usage behavior is largely driven by their individual intention to use a given technology. The intention to use a technology does not directly translate into actual usage because old habits and routines might drive employees to proceed in the old manner. The intention to use a technology can itself be predicted to a considerable degree by the perceived usefulness and the perceived ease of use of that technology (Davis et al., 1989). While perceived usefulness describes the individual employee´s cognition that utilizing the new technology would improve their job performance, perceived ease of use is defined as the employee´s perception that the IT system can be used effortlessly (Davis et al., 1989). On the left-hand side, figure 8 shows factors that increase the perceived usefulness of a technology (Venkatesh and Davis, 2000). Table 3 explains these factors in more detail.
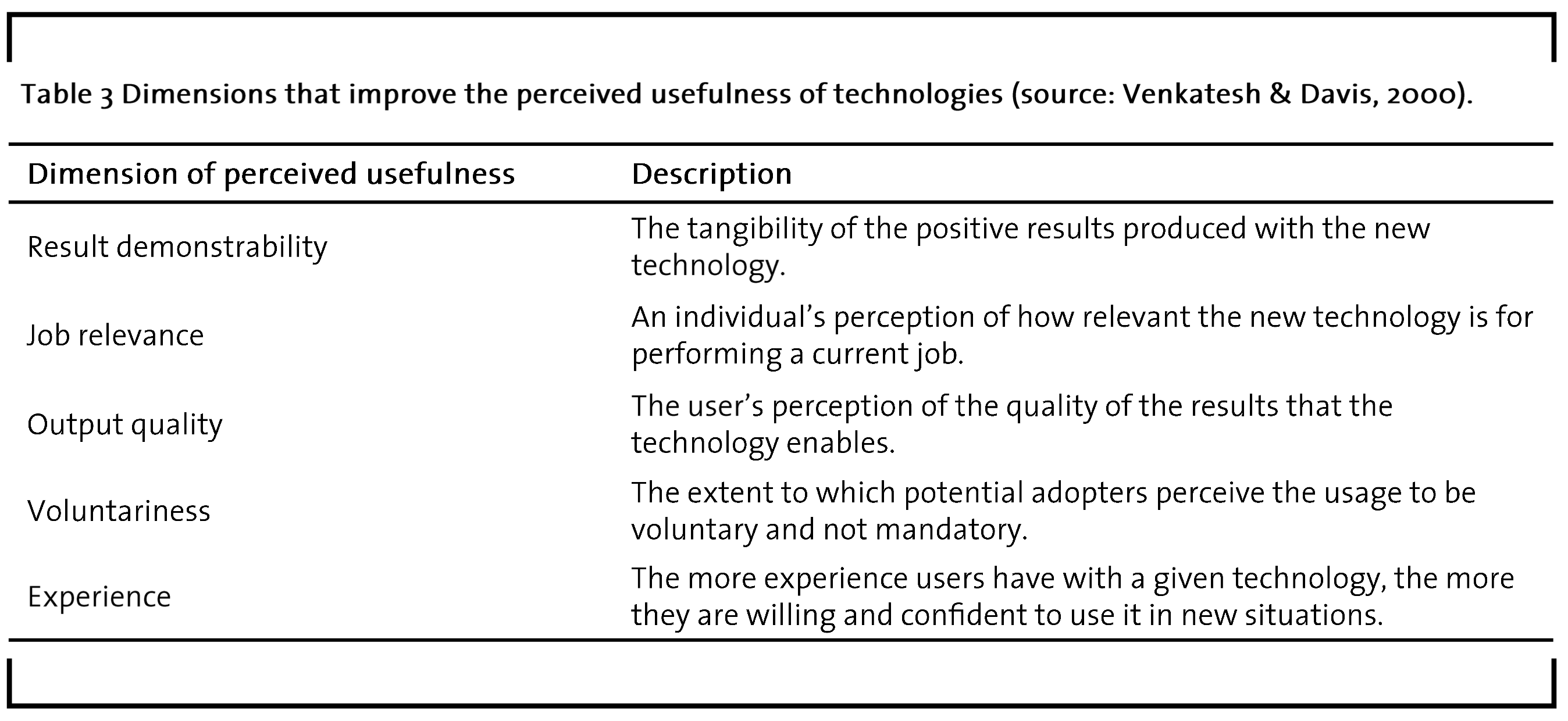
In brief, high result demonstrability, job relevance, and output quality all contribute to higher technology adoption levels (Venkatesh and Davis, 2000). Furthermore, some users are unwilling to comply with mandatory usage of new technologies, so that compliance-based introduction should be avoided (Venkatesh and Davis, 2000). Therefore, the usage of new technologies should be voluntary and adoption might be encouraged through social influence, for example by engaging in dialogue with the actual users about how the result demonstrability, job relevance, and output quality might be improved from their perspective. In addition, communicating the advantages of the new technology through a direct comparison with the old systems might increase the technology’s adoption level (Venkatesh and Davis, 2000).
In context of the case studies presented in the previous section, the technology acceptance model is applicable to different degrees. While Deep Genomics does not face issues regarding the technology adoption because they primarily employ AI experts, several established companies from the process industry might face significant barriers during the adoption process of AI. For example, implementing an AI-based Clever!Lab approach to routine lab work might provoke scepticism regarding the advantages of the technology in comparison to the costs of underlying steady audio and video surveillance, while data security concerns remain high. Insofar, managers responsible for the introduction of new technologies might bear in mind the dimensions that drive the employees’ perceived usefulness of technologies and incorporate them into the design of the system as well as clearly communicate them to potential users. Decision makers might consider nurturing a corporate culture that rewards experimentation and does not punish failure. Investments in technology are never self-sufficient and only pay off if courageous organizational employees use it as a means to take hold on the emerging opportunities (Stoffels and Leker, 2018). As all of us will inevitably become more experienced with hybrid systems combining intelligent agents with artificial neural networks e.g. in cars, smart homes, and with our mobile phones, the willingness to adopt AI at work will successively increase. However, those who vividly explore the new technological opportunities and purposefully design their applications will gain a competitive edge.
5 Conclusion
In times of declining returns from R&D in the process industries, AI not only holds the potential to incrementally improve data analysis in many cases, but might also spark new innovation by unlocking unprecedented insights into data. Going forward, researchers and practitioners need to join forces to overcome the barriers that prevent firms from leveraging the value creation potential of AI. This article therefore strives to demonstrate when specific AI methodologies are useful, discusses two case studies, and explicates how potential adoption barriers might be tackled in incumbent firms based on academic literature dedicated to the acceptance of technologies.
References
Aamodt, A., Plaza, E. (1994): Case-based reasoning: Foundational issues, method ological variations, and system approaches, Artificial Intelligence Communications, 7 (1), pp. 39–59.
Abraham, A. (2005): Rule-Based Expert Systems, Handbook of Measuring System Design.
Agatonovic-Kustrin, S., Beresford, R. (2000): Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research, Journal of Pharmaceutical and Biomedical Analysis, 22 (5), pp. 717–727.
Backhaus, K., Erichson, B., Plinke, W., Weiber, R. (2016): Multivariate Analysemethoden.
Bellifemine, Fabio Luigi, Giovanni, C., Greenwood, D. (2007): Developing multi-agent systems with JADE (Vol.7), John Wiley & Sons.
Bharadwaj, A., El Sawy, O. A., Pavlou, P. A., Venkatraman, N. (2013): Digital Business Strategy: Toward a Next Generation of Insights, MIS Quarterly, 37 (2), pp. 471–482.
Brynjolfsson, E., Rock, D., Syverson, C. (2018): Artificial Intelligence and the Modern Productivity Paradox: A Clash of Expectations and Statistics. In The Economics of Artificial Intelligence: An Agenda. University of Chicago Press.
Chui, M., Manyik, J., Miremadi, M., Henke, N., Chung, R., Nel, P., Malhotra, S. (2018): Notes from the AI frontier: Insights from hundreds of use cases. McKinsey Global Institute.
Cong, L., Ran, A. F., Cox, D., Lin, S., Barretto, R., Habib, N., Zhang, F. (2013): Multiplex genome engineering using CRISPR/Cas systems, Science, 1231143.
Davis, F. D., Bagozzi, R. P., Warshaw, P. R. (1989): User Acceptance of Computer Technology: A Comparison of Two Theoretical Models. Management Science, 35 (8), pp. 982–1003.
Evans, R., Jumper, J., Kirkpatrick, J., Sifre, L., Green, T., Qin, C., Senior, A. W. (2018): De novo structure prediction with deeplearning based scoring.
Franklin, S., & Graesser, A. (1996): Is it an angent, or just a program? A taxonomy for autonomous agents, in: International Workshop on Agent Theories, Architectures, and Languages Springer Berlin Heidelberg, pp. 21–35.
Gressling, T. (2017): A new approach to Laboratory 4: The cognitive laboratory system, in Research Gate, pp. 0–1.
Lager, T., Blanco, S., Frishammar, J. (2013): Managing R & D and innovation in the process industries, R&D Management, 43 (3), pp. 189–195.
Legris, P., Ingham, J., & Collerette, P. (2003). Why do people use information technology? A critical review of the technology acceptance model, Information and Management, 40 (3), pp. 191–204.
Leung, M. K. K., Delong, A., Alipanahi, B.,
Frey, B. J. (2016): Machine learning in genomic medicine: A review of computational problems and data sets, Proceedings of the IEEE, 104 (1), pp. 176–197.
Li, O., Liu, H., Chen, C., & Rudin, C. (2018): Deep Learning for Case-Based Reasoning through Prototypes: A Neural Network that Explains Its Predictions, Thirty-Second AAAI Conference on Artificial Intelligence.
Lohr, S. (2018): From Agriculture to Art — the A.I. Wave Sweeps, in. New York Times, available at https://www.nytimes.com/2018/10/21/busi ness/from-agriculture-to-art-the-ai-wave-sweeps-in.html.
McAfee, A., Brynjolfsson, E. (2017): Machine, platform, crowd: Harnessing our digital future. WW Norton & Company.
Mohd Ali, J., Hussain, M. A., Tade, M. O., Zhang, J. (2015): Artificial Intelligence techniques applied as estimator in chemical process systems – A literature survey, Expert Systems with Applications, 42 (14), pp. 5915–5931.
Negnevitsky, M. (2005): Artificial intelligence: A guide to intelligent systems (Second Edi), Pearson Education.
Patel, V. L., Shortliffe, E. H., Stefanelli, M., Szolovits, P., Berthold, M. R., Bellazzi, R., Abu-Hanna, A. (2009): The coming of age of artificial intelligence in medicine, Artificial Intelligence in Medicine, 46 (1), pp. 5–17.
Porter, Michael E; Heppelmann, J. E. (2014): Managing the Internet of things, Harvard Business Review, pp. 65–88.
Russell, S. J., & Norvig, P. (2010): Artificial Intelligence A Modern Approach (3.). Prentice Hall.
Segler, M. H. S., Preuss, M., Waller, M. P. (2018): Planning chemical syntheses with deep neural networks and symbolic AI, Nature, 555 (7698), pp. 604–610.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R. (2014): Dropout: A Simple Way to Prevent Neural Networks from Overfitting Nitish, Journal of Machine Learning Research, 15 (1), pp. 1929–1958.
Stoffels, M., Leker, J. (2018): The Impact of IT Assets on Innovation Performance – The Mediating Role of Developmental Culture and Absorptive Capacity, International Journal of Innovation Management, 22 (8), 1840011.
Stoffels, M., Ziemer, C. (2017): Digitalization in the process industries – Evidence from the German water industry, Journal of Business Chemistry, 14 (3), pp. 94–105.
Venkatesh, V., Davis, F. D. (2000): A Theoretical Extension of the Technology Acceptance Model: Four Longitudinal Field Studies, Management Science, 46 (2), pp. 186–204.
Wainberg, M., Merico, D., Delong, A., Frey, B. J. (2018): Deep learning in biomedicine, Nature Biotechnology, 36, 829.
Wooldridge, M. J., Jennings, N. R. (1994): Agent theories, architectures, and languages: A survey. International Workshop on Agent Theories, Architectures, and Languages, pp. 1–39.
Xiong, W., Guo, X., Yu, M., Chang, S., Zhou, B., Wang, W. Y., Barbara, S. (2018): Intelligent Agents, ArXiv Preprint.
Yoo, Y., Henfridsson, O., Lyytinen, K. (2010): Research Commentary: The New Organizing Logic of Digital Innovation: An Agenda for Information Systems Research, Information Systems Research, 21 (4), pp. 724–735.
Zhavoronkov, A. (2018): Artificial Intelligence for Drug Discovery, Biomarker Development, and Generation of Novel Chemistry, Molecular Pharmaceutics, 15 (10), pp. 4311–4313.